
Definicje dotyczące obiektowości
Zagadnienie obiektowych baz danych powstało jako efekt prac w wielu dziedzinach. Wpływ na jego rozwój miały nowe tendencje, jakie pojawiały się w obiektowych językach programowania, inżynierii oprogramowania, a także w pracach dotyczących systemów rozproszonych, systemów multimedialnych oraz komunikacji przez WWW. Nowe kierunki rozwoju zarysowały się również w technologii tradycyjnych, relacyjnych baz danych.
Obecnie występuje pewnego rodzaju zamieszanie związane ze znaczeniem obiektowości w ogóle, a znaczeniem obiektowych baz danych w szczególności. Wiele osób traktuje termin „zorientowany obiektowo” jako rodzaj modnego sformułowania, mieszczącego w sobie wiele znaczeń. Wielu ekspertów stara się określić silne, techniczne kryteria związane z terminem obiektowości, aby umożliwić rozróżnienie systemów zorientowanych obiektowo od pozostałych.
Co przemawia za wykorzystaniem obiektowości w bazach danych? Istnieje kilka koncepcji. Najbardziej popularna mówi, iż bazy danych składają się raczej z obiektów niż relacji, tabel czy innych struktur. Pojęcie „obiektu” jest rodzajem metafory, odnoszącej się do ludzkiej psychiki, sposobu w jaki ludzie myślą i postrzegają świat rzeczywisty. Ewolucja wykształciła w umysłach ludzkich mechanizmy umożliwiające nam wyodrębnianie obiektów w naszym środowisku, nazywanie ich i przyporządkowywanie im pewnych cech i zachowań. Obiektowość w technologii komputerowej, z psychologicznego punktu widzenia, jest więc oparta na wrodzonych mechanizmach ludzkiego umysłu.
Kolejnym zagadnieniem jest potrzeba obiektowości w technologii komputerowej. Przez wiele lat eksperci wskazywali na negatywny syndrom, określany mianem kryzysu oprogramowania (ang. software crisis). Kryzys oprogramowania może być przedstawiany jako efekt wzrastających kosztów produkcji oprogramowania i jego utrzymania, problemów związanych z oprogramowaniem spadkowym (ang. legacy software), ogromnym ryzykiem związanym z niepowodzeniem projektów informatycznych, niedojrzałością metod projektowania i konstrukcji oprogramowania, brakiem niezawodności, różnego rodzaju frustracjami projektantów oprogramowania i programistów i wielu tym podobnych czynników. Jednocześnie wraz z przedstawionymi zagrożeniami stale wzrasta rola systemów informatycznych jako czynników krytycznych w misji konkretnego przedsiębiorstwa.
Kryzys oprogramowania jest więc powodowany przez skomplikowanie oprogramowania i złożoność metod jego wytwarzania.
Obiektowość, będąca próbą naśladowania naturalnej psychiki człowieka, jest postrzegana jako sposób na zmniejszenie złożoności oprogramowania, a w efekcie na zredukowanie negatywnych zjawisk związanych z kryzysem oprogramowania. Ma to zostać uczynione poprzez skrócenie dystansu pomiędzy ludzkim postrzeganiem dziedziny problemu, abstrakcyjnym modelem konceptualnym dziedziny problemu (wyrażonym przykładowo za pomocą diagramu klas), a podejściem programisty zorientowanym na struktury danych i operacje. Zmniejszenie dystansu pomiędzy postrzeganiem problemu przez projektantów, a myśleniem programistów, jest uważane za najważniejszy czynnik zmniejszający złożoność analizy, projektowania, konstrukcji i utrzymania oprogramowania.
Obiektowe modele dostarczają pojęć umożliwiających analitykom i projektantom lepsze odwzorowanie problemu w abstrakcyjny schemat konceptualny. W skład tych pojęć wchodzą między innymi: złożone obiekty, klasy, dziedziczenie, kontrola typów, metody powiązane z klasami, hermetyzacja i polimorfizm. Istnieje kilka notacji i metodologii (przykładowo OMT, UML, OPEN), które pozwalają na wydajne odwzorowywanie problemu w zorientowany obiektowo model konceptualny. Z drugiej strony, systemy obiektowych baz danych oferują podobne pojęcia odnośnie struktur danych, tak więc odwzorowywanie pomiędzy modelem konceptualnym a strukturami danych jest dużo łatwiejsze, niż w przypadku tradycyjnych systemów relacyjnych.
Model obiektowy przede wszystkim dostarcza wyższego poziomu abstrakcji w sposób bardziej skuteczny, konsekwentny i jednorodny. Dotyczy on głównie struktur danych przechowywanych w obiektowej bazie danych. Wyznacza intelektualną i ideologiczną bazę pozwalającą na budowę modeli obiektowych struktur danych oraz na komunikację. Jest on spójnym zestawem własności, pojęć, terminologii, notacji i formalizmów służących do:
porozumiewania się profesjonalistów,
uczenia i objaśniania metod i technik obiektowych,
budowy języków, systemów, interfejsów,
budowy i objaśniania zasad analizy i projektowania obiektowego.
W stosunku do modelu relacyjnego, obiektowość wprowadza znacznie więcej pojęć, często o niezbyt precyzyjnej semantyce. Z jednej strony obiektowość stara się uogólnić i rozszerzyć ideologiczne założenia modelu danych, z drugiej strony stara się objąć nimi te pojęcia, które w modelu relacyjnym nie dały się wyrazić.
W chwili obecnej nie istnieje jeden, ogólnie przyjęty, standard jednoznacznie definiujący pojęcia obiektowe. Trwają prace nad ustandaryzowaniem pojęć obiektowych w dziedzinie baz danych, prowadzone między innymi przez ODMG.
Brak powszechnie akceptowalnych definicji modelu obiektowego w dziedzinie baz danych wynika z faktu, iż rozwój podejścia obiektowego następował w trzech różnych obszarach:
językach programowania,
sztucznej inteligencji,
bazach danych.
W różnych językach programowania i reprezentacji wiedzy przyjęto różne interpretacje pojęć obiektowych. Jednak mimo to, obiektowe języki programowania i reprezentacji wiedzy zawierają wiele spójnych pojęć obiektowych, na podstawie których można stworzyć podstawowy, obiektowy model danych.
Przedstawione poniżej pojęcia są podstawowymi dla obiektowości i według [Kim 1996] wchodzą w skład podstawowego modelu obiektowego:
obiekt,
identyfikator obiektu,
tożsamość obiektu,
klasa,
atrybut,
metoda,
komunikat,
hermetyzacja,
hierarchia klas i dziedziczenie.
W kolejnych rozdziałach pracy zostaną przybliżone przedstawione powyżej pojęcia.
Obiekt
Obiekt (ang. object) jest podstawowym pojęciem dla obiektowości. W pracy [Subieta 1999a] obiekt jest definiowany jako abstrakcyjny byt, reprezentujący lub opisujący pewną rzecz lub pojęcie obserwowane w świecie rzeczywistym. Obiekt jest odróżnialny od innych obiektów, ma nazwę i dobrze określone granice.
Obiektem może być także pewna abstrakcja programistyczna. Mogą istnieć obiekty programistyczne, które nie posiadają swoich odpowiedników w świecie rzeczywistym. Obiektem może być pewien zamknięty fragment oprogramowania (dana, procedura, moduł itp.), którymi programista może operować jak pewną zwartą bryłą. Obiektom przypisuje się cechy takie jak: tożsamość, stan i operacje. Obiekt posiada nazwę, jednoznaczną identyfikację, określone granice, atrybuty i inne własności.
Tenże autor uważa, iż wiele prac nie różnicuje pojęcia obiektu jako pewnej abstrakcji pojęciowej lub informacyjnej, struktury danych określanej jako „obiekt” przechowywanej wewnątrz komputera oraz konkretnego obiektu istniejącego w świecie rzeczywistym. Stwierdza on jednak, iż z metodologicznego punktu widzenia takie rozróżnienie jest konieczne i wynika zwykle z kontekstu.
Przykładami obiektów ze świata rzeczywistego są: miasto Kraków, faktura, konkretna osoba czy model samochodu. Obiektami nie są przykładowo: śnieg, woda, piasek.1
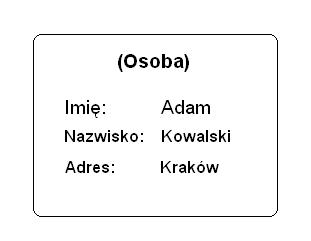
RYSUNEK 2.1. GRAFICZNA PREZENTACJA OBIEKTU.
Identyfikator obiektu
Opierając się na definicji przedstawionej przez [Subieta 1999a], identyfikator obiektu (ang. object identifier) jest to unikalna wewnętrzna nazwa obiektu, nadawana automatycznie przez system i nie posiadająca znaczenia w świecie zewnętrznym. Służy on do odróżnienia obiektu od innych obiektów oraz do budowy odwołań prowadzących do obiektu.
[Lausen 2000] stwierdza, iż identyfikator przypisany do obiektu pozostaje niezmienny w całym cyklu jego życia. W konsekwencji identyfikator obiektu jest różny od jego wartości, która może ulegać zmianom.
W pracy [Subieta 1999a] poruszony jest także problem unikalności identyfikatorów. Autor uważa, iż pojęcie unikalnego identyfikatora obiektu staje się dość trudne w przypadku istnienia wielu kopii tego samego obiektu, lub w przypadku istnienia wielu wersji obiektu. Istnienie unikalnych identyfikatorów obiektów czyni w zasadzie zbędnym pojęcie klucza2, występujące w modelu relacyjnym.
Zdarza się, że identyfikator obiektu jest związany logicznie z adresem miejsca przechowywania obiektu. Jednakże związek tego rodzaju jest uważany za niekorzystny jeśli chodzi o elastyczność w zakresie ulokowania obiektu, z drugiej jednak strony bywa konieczny z uwagi na wymaganą wydajność.
[Ludwikowska 2000] dodaje, iż identyfikator obiektu jest ważnym elementem semantyki języków dostępu i manipulacji obiektami. W praktyce nie występuje bezpośrednie posługiwanie się wartością identyfikatora obiektu, lecz wykorzystywane jest pewne oznaczenie symboliczne, przykładowo nazwa obiektu, które następnie w procesie wiązania jest zmieniane na jego identyfikator.
Tożsamość obiektu
Tożsamość obiektu (ang. identity) jest pojęciem ściśle wiążącym się ze zdefiniowanym wcześniej pojęciem identyfikatora obiektu.
Oznacza ono, iż obiekt istnieje i jest odróżnialny od innych obiektów niezależnie od jego aktualnego stanu, który może się zmieniać. Tożsamość obiektu jest kategorią filozoficzną, która nie jest wiązana z jakimkolwiek zestawem atrybutów obiektu lub jego aktualnym stanem. Dopuszczalne jest istnienie dwóch różnych obiektów o identycznych wartościach atrybutów. W praktyce tożsamość oznacza istnienie unikalnego wewnętrznego identyfikatora, nie ulegającego zmianom w trakcie życia obiektu. Tożsamość obiektu jest niezależna od jego lokacji w świecie rzeczywistym lub w przestrzeni adresowej komputera [Subieta 1999a].
Klasa
Wszystkie obiekty mające ten sam zbiór atrybutów i metod, mogą zostać zgrupowane w jednej klasie. Obiekt należy do klasy jako jej instancja (wystąpienie). Klasa stanowi wzorzec dla tworzonego obiektu. Klasa jest również bytem semantycznym, rozumianym jako miejsce przechowywania, specyfikacji i definicji takich cech grupy podobnych obiektów, które są dla nich niezmienne: atrybuty, metody, ograniczenia dostępu, dozwolone operacje na obiektach, wyjątki.
W systemach obiektowych klasa jest traktowana jako obiekt klasowy w celu zagwarantowania jednolitego posługiwania się komunikatami. W związku z tym, z klasą mogą być związane atrybuty i metody klasowe (statyczne). W atrybutach takich przechowywane są wartości wspólne dla wszystkich obiektów tej klasy [Ludwikowska 2000].
Istnieje wiele rodzajów klas. Do najważniejszych z nich można zaliczyć: klasę abstrakcyjną oraz klasę konkretną.
Pojęcie klasy abstrakcyjnej (ang. abstract class) jest uważane za jedno z podstawowych dla obiektowości, wzmacniające zarówno mechanizmy abstrakcji pojęciowej, jak i możliwości ponownego użycia. Klasa abstrakcyjna zawiera własności, które są dziedziczone przez jej podklasy, ale jednocześnie nie posiada bezpośrednich wystąpień obiektów. Stanowi ona wyższy poziom abstrakcji podczas rozpatrywania pewnego zestawu obiektów. Najczęściej wykorzystuje się klasy abstrakcyjne do zdefiniowania wspólnego interfejsu dla pewnej liczby podklas. Klasa abstrakcyjna może posiadać metody, które są wyspecyfikowane w jej wnętrzu, a których implementacja jest oczekiwana w jej bezpośrednich lub pośrednich podklasach.
W odróżnieniu od klasy abstrakcyjnej, klasa konkretna (ang. concrete class) może posiadać bezpośrednie wystąpienia obiektów.
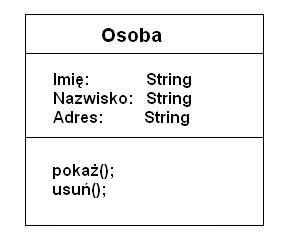
RYSUNEK 2.2. GRAFICZNA PREZENTACJA KLASY.
Atrybut
Atrybuty (ang. attributes), będące częścią definicji klasy, poprzez przypisywane im wartości tworzą stan obiektu. Atrybuty obiektu są analogiczne do atrybutów (kolumn) krotki relacji w relacyjnych bazach danych. Dziedziną atrybutu może być jakakolwiek klasa, wliczając w to klasy wartości pierwotnych (np. integer, string itp.). Z powyższego faktu wynika zagnieżdżona struktura definicji klasy. Klasa składa się ze zbioru atrybutów, dziedzinami których mogą być inne klasy z ich własnymi zbiorami atrybutów, itd. W wyniku tego definicja klasy określa skierowany graf klas o korzeniu w tej klasie [Kim 1996].
W literaturze pojawia się wiele rodzajów atrybutów. Wśród nich można wyróżnić [Subieta 1999a]:
atrybut prosty (ang. simple attribute, atomic attribute) – przechowuje dokładnie jedną wartość, będącą z punktu widzenia użytkownika wartością niepodzielną (atomową).
atrybut złożony (ang. complex attribute, composite attribute) – przechowuje wiele wartości niepodzielnych (atomowych). Atrybut taki może posiadać strukturę hierarchiczną.
atrybut klasowy (ang. class attribute) – nazywany także statycznym. Nazwa i wartość takiego atrybutu jest wspólna dla wszystkich wystąpień danej klasy.
atrybut powtarzalny (ang. repeating attribute) – przechowuje zestaw wartości o nieokreślonej i zmiennej w czasie liczbie elementów.
atrybut pochodny (ang. derived attribute) – nazywany także wyliczalnym. Przechowuje wartość, która jest wyliczana na podstawie innych atrybutów, bądź też innych danych.
atrybut wskaźnikowy (ang. pointer attribute) – atrybut, którego wartością jest wskaźnik prowadzący zwykle do pewnego obiektu.
atrybut opcyjny (ang. optional attribute) – atrybut, którego wartość może być pusta, lub który może być nieobecny w konkretnym wystąpieniu obiektu. Opcyjność może dotyczyć atrybutu dowolnego rodzaju. Atrybut ten można uważać za specjalny przypadek atrybutu powtarzalnego, w którym liczba elementów zestawu wartości wynosi zero lub jeden.
atrybut domyślny (ang. default attribute) – atrybut ten wiąże się pojęciowo z przedstawionym wcześniej atrybutem opcyjnym. Oznacza on wartość przyjmowaną domyślnie, o ile nie została wstawiona żadna inna wartość.
Metoda
Metoda (ang. method) to procedura, funkcja lub operacja przypisana do klasy obiektów i dziedziczona przez jej podklasy. Identyfikacja stanu obiektu oraz identyfikacja zmiany stanu obiektu są możliwe dzięki metodom związanym z danym obiektem. W przypadku idealnym, metody zdefiniowane przez programistę powinny być jedynym sposobem dostępu do obiektu.
Metoda jest abstrakcją programistyczną tej samej kategorii co procedura lub procedura funkcyjna. Metoda, w przeciwieństwie do procedury, działa w środowisku obiektu po wysłaniu do niego komunikatu zawierającego nazwę tej metody. Metoda wykorzystuje wewnętrzne informacje tego obiektu, jakimi są przede wszystkim wartości atrybutów.
Z koncepcyjnego punktu widzenia miejscem przechowywania metody jest odpowiednia klasa. Oznacza to, że metoda takowa może zostać zastosowana do dowolnego obiektu będącego instancją tej klasy.
Istnieje kilka charakterystycznych metod posiadających odrębne nazewnictwo.
Zaliczyć do nich można następujące rodzaje metod:
metoda abstrakcyjna (ang. abstract method) – jest to metoda, której specyfikacja znajduje się w danej klasie, ale której implementacje znajdują się w podklasach.
metoda fabrykująca (ang. factory method) – nazywana inaczej konstruktorem. Służy do tworzenia nowych obiektów.
metoda klasowa (ang. class method) – metoda ta nie działa na pojedynczych wystąpieniach danej klasy (obiektach), lecz na całej ekstensji klasy.
Komunikat
Komunikat (ang. message) jest sygnałem skierowanym do obiektu, wywołującym określoną metodę lub operację, którą należy wykonać na obiekcie.
Nazwa użyta w komunikacie jest nazwą wywoływanej metody. Źródłem komunikatu jest działający aktualnie program, w szczególności może to być wykonywana aktualnie metoda. Komunikat może posiadać parametry; zwykle jest ich co najwyżej kilka, w każdym razie parametry komunikatu nie służą do przenoszenia większej ilości informacji. Obiekt otrzymujący komunikat wykonuje odpowiednią metodę, która to metoda może zmienić jego stan. W efekcie wykonania metody na obiekcie, który otrzymał komunikat, może zostać zwrócona odpowiedź do nadawcy komunikatu.
W wielu opracowaniach uważa się, że zarówno komunikat, jak i nazwy występujące w ciele metody są dynamicznie wiązane, w związku z czym ten sam komunikat może zostać wysłany do różnych obiektów i może wywołać różne metody. Fakt ten posiada istotne znaczenie dla metod oraz technik projektowania i programowania [Subieta 1999a].
Hermetyzacja
Hermetyzacja (ang. encapsulation) polega na grupowaniu elementów składowych w obrębie jednej bryły i umożliwieniu manipulowania tą bryłą jako całością. Hermetyzacja wiąże się z ukrywaniem pewnych informacji dotyczących struktury i implementacji wnętrza tej bryły [Ludwikowska 2000].
Hermetyzacja jest podstawową techniką abstrakcji, czyli ukrycia wszelkich szczegółów danego przedmiotu lub bytu programistycznego, które na danym etapie rozpatrywania (analizy, projektowania, programowania) nie stanowią jego istotnej charakterystyki [Subieta 1999a].
Pojęcie hermetyzacji, jako jedna z zasad inżynierii oprogramowania, zostało sformułowane przez D. Parnasa w roku 1975.
Można wyróżnić dwie koncepcje hermetyzacji: hermetyzacja ortodoksyjna oraz hermetyzacja ortogonalna.
Pierwsza z nich, hermetyzacja ortodoksyjna, jest dość popularnym stereotypem w obiektowości. Ten rodzaj hermetyzacji został zaimplementowany między innymi w języku Smalltalk. W tym podejściu wszelkie operacje, jakie można wykonać na obiekcie, są określone przez metody do niego przypisane (znajdujące się w jego klasie i nadklasach). Bezpośredni dostęp do atrybutów obiektu jest niemożliwy.
Drugim rodzajem jest hermetyzacja ortogonalna, zaimplementowana między innymi w językach C++ i Eiffel. W tym przypadku dowolny atrybut i metoda obiektu mogą być prywatne (czyli niedostępne z zewnątrz), bądź też publiczne.
Hierarchia klas i dziedziczenie
Klasy w systemie tworzą hierarchię klas (ang. class hierarchy). Oznacza to, że dla pewnej klasy A może istnieć inna klasa (jedna lub więcej) B, znajdująca się na niższym poziomie, która jest uszczegółowieniem (specjalizacją) klasy B. Natomiast klasa A, będąca na wyższym poziomie w hierarchii, jest uogólnieniem (generalizacją) klasy (klas) B. Klasa B dziedziczy wszystkie atrybuty i metody klasy A, mogąc jednocześnie posiadać własne atrybuty i metody. Określone dla klasy A atrybuty i metody są rekurencyjnie dziedziczone przez wszystkie jej podklasy (rys. 2.3).
Większość systemów obiektowych posiada predefiniowaną przez system klasę, stanowiącą jedyny korzeń dla wszystkich klas w systemie. Hierarchia klas jest spójna, co oznacza, że nie istnieją odizolowane węzły, natomiast do każdego węzła (klasy) istnieje dostęp z korzenia.
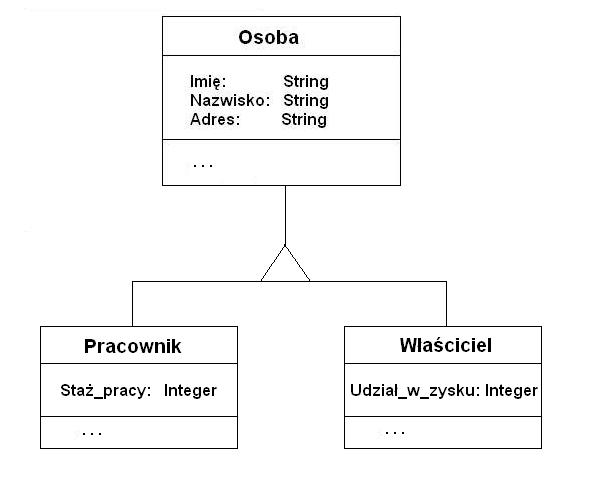
RYSUNEK 2.3. HIERARCHIA KLAS I DZIEDZICZENIE.
Cechą wspólną dla wszystkich bez wyjątku systemów obiektowych jest to, że klasa może posiadać dowolną liczbę podklas. Jednakże w pewnych systemach klasy mogą mieć tylko jedną nadklasę, natomiast w innych klasy mogą mieć dowolną liczbę nadklas.
Pierwszy przypadek, kiedy klasa dziedziczy atrybuty i metody od tylko jednej klasy, nazywany jest dziedziczeniem pojedynczym (ang. single inheritance). W sytuacji takiej każda klasa ma co najwyżej jedną nadklasę.
Drugi przypadek dotyczy klasy, która dziedziczy atrybuty i metody od więcej niż jednej nadklasy. Sytuacja taka nosi nazwę dziedziczenia wielokrotnego (ang. multiple inheritance). Jeżeli system umożliwia wielokrotne dziedziczenie, wówczas klasy tworzą zakorzeniony spójny skierowany graf acykliczny, nazywany czasem kratą klas. Nie ma porozumienia odnośnie tego, czy wielokrotne dziedziczenie jest naprawdę konieczne. Jednakże pomimo tego, iż ten rodzaj dziedziczenia komplikuje model danych, wydaje się, że jest ono potrzebne i jego zaakceptowanie jest nieuniknione [Kim 1996].
Metody odziedziczone mogą zostać przeciążone. Oznacza to, iż podklasa może zmodyfikować działanie odziedziczonej metody nie zmieniając jej nazwy.
Pojęcie dziedziczenia stwarza pewne problemy, takie jak: konflikty nazw, zasięg dziedziczenia, naruszenia hermetyzacji. Są to jednak sytuacje charakterystyczne dla programowania obiektowego, dlatego nie należy ich traktować jako wady rzutujące negatywnie na decyzje, czy stosować dziedziczenie.
Pojęcia wykraczające poza model podstawowy
Przedstawione powyżej pojęcia wchodzące w skład podstawowego modelu obiektowego w większości przypadków zaspokajają podstawowe wymagania dotyczące modelowania danych. Istnieje jednak wiele ważnych pojęć, które są istotne w wielu przypadkach, ale które nie należą do pojęć podstawowych.
W tym rozdziale postaramy się przedstawić trzy z takich pojęć. Są to: polimorfizm, obiekty złożone oraz zarządzanie wersjami.
Polimorfizm (ang. polymorphism) w terminologii obiektowej oznacza możliwość istnienia wielu metod o takiej samej nazwie, powiązaną z możliwością wyboru konkretnej metody podczas czasu wykonania (dynamicznego wiązania).
Wybór nazwy jest określany wyłącznie jej zewnętrznym, pojęciowym znaczeniem w ramach danej klasy obiektów. Wybór ten nie jest uwarunkowany własnościami lub istnieniem innych klas. Identyczny komunikat wysłany do różnych obiektów może wywołać różne metody.
Obiekt złożony (ang. complex object, composite object) składa się z innych obiektów. Obiekty takowe wywodzą się z obiektów atomowych lub już skonstruowanych za pomocą pewnych konstruktorów. W celu obsługi obiektów złożonych muszą zostać dostarczone odpowiednie operatory na nich operujące. W szczególności, musi istnieć możliwość działania na całych obiektach lub też tylko na ich części.
Obiekty złożone posiadają wewnętrzną strukturę, czyli składają się z prostszych składników. Wartości składników mogą być częścią wartości obiektu lub wiązać się z obiektem za pomocą odwołań. Zaletą tej ostatniej procedury jest możliwość powtórnego użycia informacji poprzez dzielenie obiektów.
Obiekty złożone w naturalny sposób występują w większości dziedzin zastosowania systemów baz danych. Dostępne obecnie obiektowe systemy baz danych w szerokim zakresie obsługują obiekty złożone [Lausen 2000].
Trzecim z kolei pojęciem jest zarządzanie wersjami.3 Funkcjonalność systemu obiektowych baz danych musi objąć szereg żądań o szerszym zakresie niż stawiane systemom konwencjonalnym. Wynika to głównie z nowych obszarów, w których może mieć zastosowanie ten nowy typ baz danych. Przykładowo w aplikacjach CAD lub CASE, występują wersje poszczególnych obiektów projektu, które są tworzone i ewentualnie odrzucane podczas procesu projektowania. Wersje obiektów są łączone w konfiguracje, które w efekcie mogą dać produkty do wytworzenia. Jeśli system bazy danych ma właściwie obsługiwać taki rodzaj środowiska, musi oferować zarządzanie wersjami [Lausen 2000].
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.